
返回 
人工智能
CLUE中文语言理解测评基准
CLUE(Chinese Language Understanding Evaluation)是一个专注于中文语言理解任务的开源测评基准,旨在通过提供全面的数据集、标准化测评和排行榜,推动中文NLP技术的发展,并精准量化通用人工智能(AGI)的进展。
产品简介
CLUE(Chinese Language Understanding Evaluation)是一个专注于中文语言理解任务的开源测评基准,旨在通过提供全面的数据集、标准化测评和排行榜,推动中文NLP技术的发展,并精准量化通用人工智能(AGI)的进展。
产品截图
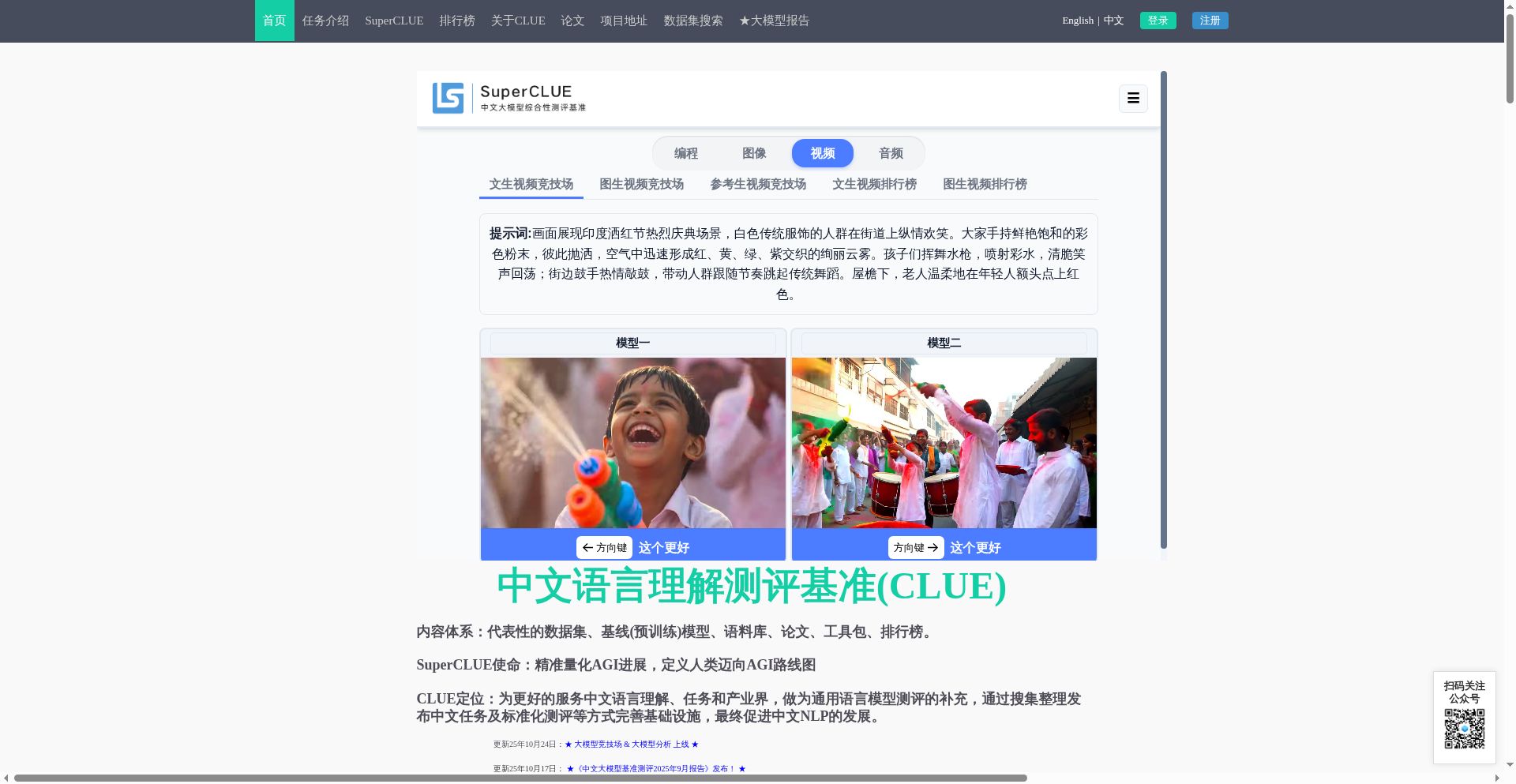
详细介绍
产品概述
CLUE(Chinese Language Understanding Evaluation)中文语言理解测评基准是一个旨在服务中文语言理解、任务和产业界的非营利性开源项目。其定位是作为通用语言模型测评的重要补充,通过搜集、整理和发布中文任务数据集及标准化测评体系,构建完善的中文NLP基础设施。目标用户包括人工智能研究人员、大模型开发者、企业技术团队以及对中文AI能力评估有需求的各方。其核心使命是精准量化AGI(通用人工智能)的发展进程,并定义人类迈向AGI的路线图。
核心功能与特点
CLUE基准的核心是一个多层次、多维度的测评体系,主要包括以下功能与特点:
- SuperCLUE通用大模型测评:这是其核心测评框架,定期发布涵盖推理、代码、数学、多轮对话等能力的综合榜单。
- 垂直领域专项测评:针对特定行业和应用场景开发了系列专项测评基准,包括但不限于:
- SuperCLUE-Industry(工业大模型)
- SuperCLUE-Finance(金融大模型)
- SuperCLUE-Auto(汽车行业/智能座舱)
- SuperCLUE-RAG(检索增强生成)
- 能力维度专项测评:深入评估大模型的特定能力,例如:
- SuperCLUE-Code3(代码生成)
- SuperCLUE-Math6(数学推理)
- SuperCLUE-Video(文生视频)
- SuperCLUE-Agent(智能体)
- SuperCLUE-Safety(安全对抗)
- SuperCLUE-Long(长文本理解)
- 数据集与工具开源:提供用于测评的多样化中文数据集、基线模型和工具包,所有资源在GitHub上开源。
- 定期报告与榜单发布:持续追踪模型进展,定期(如月度、年度)发布详细的测评分析报告和实时更新的排行榜。
- 竞技场(Arena)模式:引入了基于用户投票的模型匿名对比平台(琅琊榜),提供更直观的模型能力对比。
优势
CLUE基准在中文AI测评领域具有显著优势:
- 中文原生与专业性:专门针对中文语言特点和任务设计,测评体系更贴合中文NLP的实际需求,弥补了国际通用基准在中文语境下的不足。
- 全面性与系统性:测评范围覆盖通用能力与垂直领域,形成了一套从基础理解到复杂应用,从单一模态到多模态的完整测评矩阵。
- 客观性与公信力:作为独立的第三方测评基准,其开源、透明的测评方法和数据集,建立了较高的行业公信力,被众多主流模型团队引用和认可。
- 前瞻性与引领性:紧密跟踪技术前沿,快速响应并定义新的测评维度(如Agent、RAG、多模态交互等),引领中文大模型的评测方向。
- 社区驱动与持续迭代:拥有活跃的社区,测评项目不断根据技术发展和社区反馈进行更新与扩充,保持其时效性和相关性。
应用场景
CLUE基准的应用场景广泛,主要服务于以下领域:
- 大模型研发与优化:AI公司和研究机构可使用CLUE的测评结果客观评估自家模型在中文任务上的性能短板,指导模型迭代与优化方向。
- 技术选型与采购参考:企业用户在选型大模型产品或服务时,可依据CLUE的排行榜和专项测评报告,进行横向对比,做出更明智的决策。
- 学术研究与论文发表:研究人员可将CLUE作为标准测评平台,在学术论文中引用其榜单数据,以验证所提模型或方法的有效性。
- 行业落地与能力评估:特定行业(如金融、工业、汽车)的用户可以利用相应的专项测评基准(如SuperCLUE-Finance, SuperCLUE-Industry)来评估大模型在业务场景中的适用性和成熟度。
- 投资分析与市场洞察:投资机构和分析师可通过CLUE定期发布的报告和榜单,追踪AI技术发展趋势,评估不同公司的技术实力和市场地位。
相关工具



