
返回 
人工智能
PubMedQA
PubMedQA 是一个面向生物医学研究问答的数据集,提供 1k 人工标注、61.2 万未标注及 211.3 万人工生成的 Yes/No/Maybe 类型问答,用于评估和训练医学领域的语言模型。
产品简介
PubMedQA 是一个面向生物医学研究问答的数据集,提供 1k 人工标注、61.2 万未标注及 211.3 万人工生成的 Yes/No/Maybe 类型问答,用于评估和训练医学领域的语言模型。
产品截图
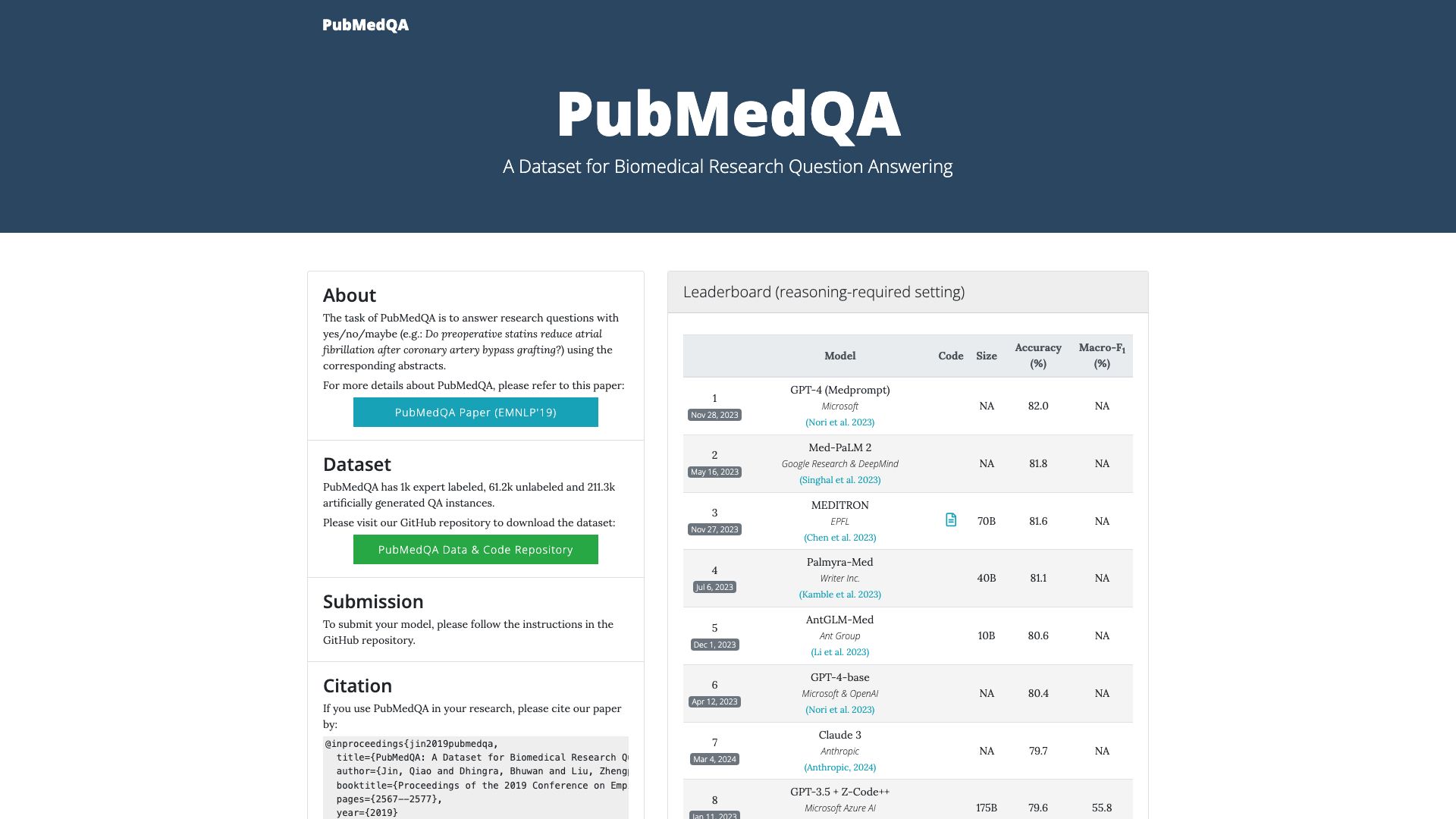
详细介绍
产品概述
PubMedQA 旨在为生物医学研究问答提供统一的基准数据集,帮助科研人员、模型研发者以及自然语言处理社区在医学文献摘要上实现 yes/no/maybe 的自动回答。该数据集聚焦医学研究问题的快速检索与推理,适用于学术研究与实际应用场景。
核心功能与特点
- 任务定义:基于对应的 PubMed 摘要,回答研究问题的 Yes、No 或 Maybe 三选一。
- 数据规模:包括 1,000 条专家标注实例、61.2 万条未标注实例以及 211.3 万条人工生成的 QA 实例,覆盖广泛的医学主题。
- 获取方式:可通过官方 GitHub 仓库下载完整数据及配套代码。
- 基准评测:提供公开的 Leaderboard,列出多种模型在推理需求设置下的准确率与 Macro‑F1 分数,便于直接对比。
- 学术引用:对应论文已在 EMNLP'19 发表,提供完整的引用格式供研究使用。
优势
- 高质量标注:专家标注的 1k 实例确保答案的可靠性,适合作为模型微调的黄金标准。
- 规模与多样性:大规模未标注和合成数据为半监督学习提供了丰富的资源,提升模型的泛化能力。
- 统一评测平台:Leaderboard 汇总了多家机构的最新模型成绩,帮助研究者快速定位性能瓶颈。
- 开源生态:数据与代码均在 GitHub 公开,便于社区复现、扩展和二次开发。
应用场景
- 医学问答模型训练:作为训练集或微调集,提升模型在医学文献推理上的准确性。
- 模型评估与基准:利用 Leaderboard 对新模型进行性能对比,验证创新方法的有效性。
- 科研辅助工具:帮助研究人员快速判断文献中是否已有答案,节约文献检索时间。
- 教育与教学:用于医学信息检索课程的案例数据,演示自然语言处理在专业领域的应用。
相关工具



